Brewer's CAP Theorem for Non-Techies
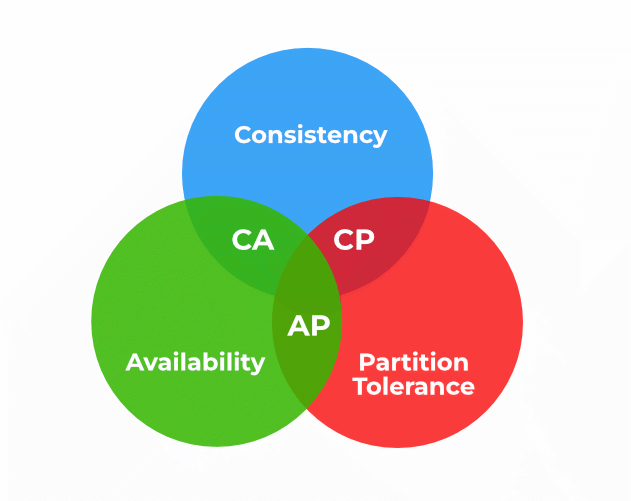
Brewer’s CAP theorem explains the different approaches to storing and retrieving large quantities of data. It basically says that you can just pick 2 of the 3 following characteristics for your distributed data architecture, where the job of the “database” is spread across multiple machines (aka “nodes”).
- Consistency – All nodes see the same data at the same time. If data changes on Node A, then it also immediately changes on Node B.
- Availability – If one node (machine) fails, it doesn’t prevent surviving nodes from continuing to operate.
- Partition Tolerance – No failures less than total network failures can cause the system to fail.
The "CAP" in "Brewer's CAP Theorem" gets its names from the first intial of these three properties.
Note that Brewer’s CAP Theorem applies to all distributed data systems – where you spread both the processing load and the data storage across multiple machines.
Now, when I first encountered Brewer’s CAP Theorem, "Consistency" and "Availablity" seemed intuitive to me. But I was perplexed by "Partition Tolerance". I mean, how exactly was it different than "Availability"? To my uneducated ears, Partition Tolerance and Availability sounded the same – they were both about gracefully handling failures so the rest of the system can keep operating.
The difference is this:
- "Availability" covers the failure of a node/machine, such as a machine crashing or the “data service” on a machine dying.
- Partition Tolerance" covers the failure of the network, and not just individual nodes.
So, two machines/nodes can be in perfect working order and completely “Available.” But if these nodes are unable to communicate with each other even temporarily, then a new transaction on Node A won’t get immediately reflected on Node B, no matter how healthy both Nodes A and B are. Thus, the Partition Tolerance clause is violated.
It is not surprising that I couldn’t wrap my head around “Partition Tolerance” at first, seeing as my background was mainly in Relational Databases. When clustered, traditional RDBMSs ensure both Consistency of the data they store and the Availability of database cluster nodes. RDBMS’s don’t do Partition Tolerance, though.
http://blog.nahurst.com/visual-guide-to-nosql-systems
If you want to scale out a database horizontally – that is, by just adding more machines to your system (as opposed to “scaling up” by adding more CPU/memory/network/disk within each machine), then you need to focus on Partition Tolerance, or else do architectural gymnastics.
Many systems choose CP (Consistent + Partition Tolerant) over CA (Consistent + Available) because choosing CA would mean to potentially block the whole cluster in case of network partitions (i.e. some nodes are unreachable by the others). Choosing CP instead means that the system is allowed to put partitioned nodes “out” of the cluster (making them unavailable), so the remaining nodes can continue working.
For a more detailed explanation: